Fast Pattern Matching#
![]()
Beyond Matrix Profiles#
At the core of STUMPY, one can take any time series data and efficiently compute something called a matrix profile, which essentially scans along your entire time series with a fixed window size, m, and finds the exact nearest neighbor for every subsequence within your time series. A matrix profile allows you to determine if there are any conserved behaviors (i.e., conserved subsequences/patterns) within your data and, if so, it can tell you exactly where they are located within your time series. In a previous tutorial, we demonstrated how to use STUMPY to easily obtain a matrix profile, learned how to interpret the results, and discover meaningful motifs and discords. While this brute-force approach may be very useful when you don’t know what pattern or conserved behavior you are looking but, for sufficiently large datasets, it can become quite expensive to perform this exhaustive pairwise search.
However, if you already have a specific user defined pattern in mind then you don’t actually need to compute the full matrix profile! For example, maybe you’ve identified an interesting trading strategy based on historical stock market data and you’d like to see if that specific pattern may have been observed in the past within one or more stock ticker symbols. In that case, searching for a known pattern or “query” is actually quite straightforward and can be accomplished quickly by using the wonderful stumpy.mass function in STUMPY.
In this short tutorial, we’ll take a simple known pattern of interest (i.e., a query subsequence) and we’ll search for this pattern in a separate independent time series. Let’s get started!
Getting Started#
Let’s import the packages that we’ll need to load, analyze, and plot the data
%matplotlib inline
import pandas as pd
import stumpy
import numpy as np
import numpy.testing as npt
import matplotlib.pyplot as plt
from matplotlib.patches import Rectangle
plt.style.use('https://raw.githubusercontent.com/stumpy-dev/stumpy/main/docs/stumpy.mplstyle')
Loading the Sony AIBO Robot Dog Dataset#
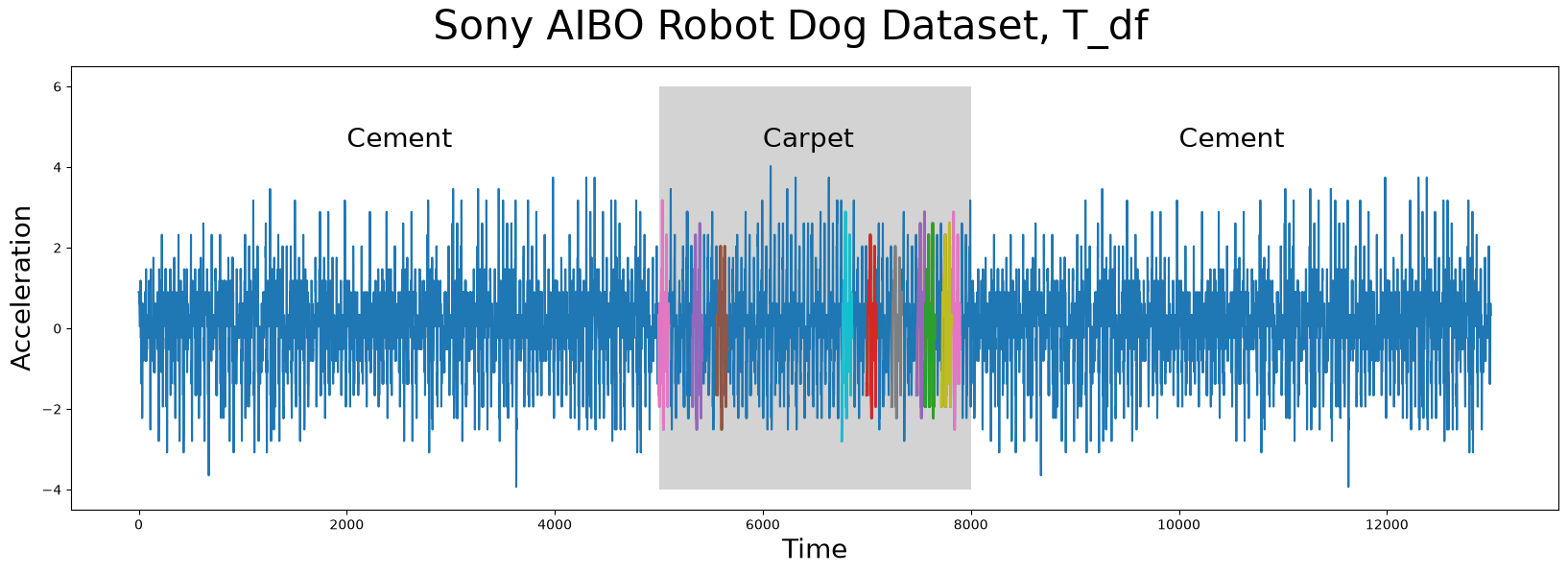
The time series data (below), T_df, has n = 13000 data points and it was collected from an accelerometer inside of a Sony AIBO robot dog where it tracked the robot dog when it was walking from a cement surface onto a carpeted surface and, finally, back to the cement surface:
T_df = pd.read_csv("https://zenodo.org/record/4276393/files/Fast_Pattern_Searching_robot_dog.csv?download=1")
T_df.head()
| Acceleration | |
|---|---|
| 0 | 0.89969 |
| 1 | 0.89969 |
| 2 | 0.89969 |
| 3 | 0.89969 |
| 4 | 0.89969 |
Visualizing the Sony AIBO Robot Dog Dataset#
plt.suptitle('Sony AIBO Robot Dog Dataset, T_df', fontsize='30')
plt.xlabel('Time', fontsize ='20')
plt.ylabel('Acceleration', fontsize='20')
plt.plot(T_df)
plt.text(2000, 4.5, 'Cement', color="black", fontsize=20)
plt.text(10000, 4.5, 'Cement', color="black", fontsize=20)
ax = plt.gca()
rect = Rectangle((5000, -4), 3000, 10, facecolor='lightgrey')
ax.add_patch(rect)
plt.text(6000, 4.5, 'Carpet', color="black", fontsize=20)
plt.show()
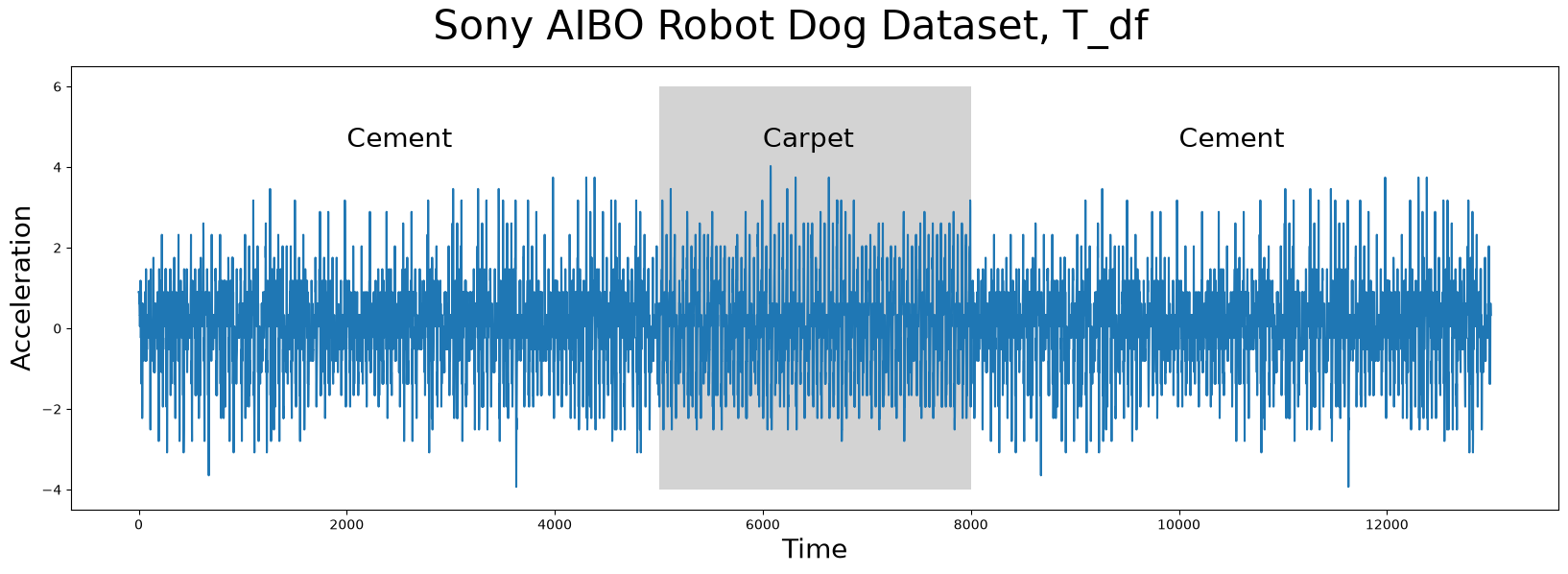
In the plot above, the periods of time when the robot dog was walking on cement is displayed with a white background while the times when the robot dog was walking on carpet is highlighted with a grey background. Do you notice any appreciable difference(s) between walking on the different surfaces? Are there any interesting insights that you can observe with the human eye? Do any conserved patterns exist within this time series and, if so, where are they?
Have You Seen This Pattern?#
The subsequence pattern or query (below) that we are interested in searching for in the time series (above) looks like this:
Q_df = pd.read_csv("https://zenodo.org/record/4276880/files/carpet_query.csv?download=1")
plt.suptitle('Pattern or Query Subsequence, Q_df', fontsize='30')
plt.xlabel('Time', fontsize ='20')
plt.ylabel('Acceleration', fontsize='20')
plt.plot(Q_df, lw=2, color="C1") # Walking on cement
plt.show()
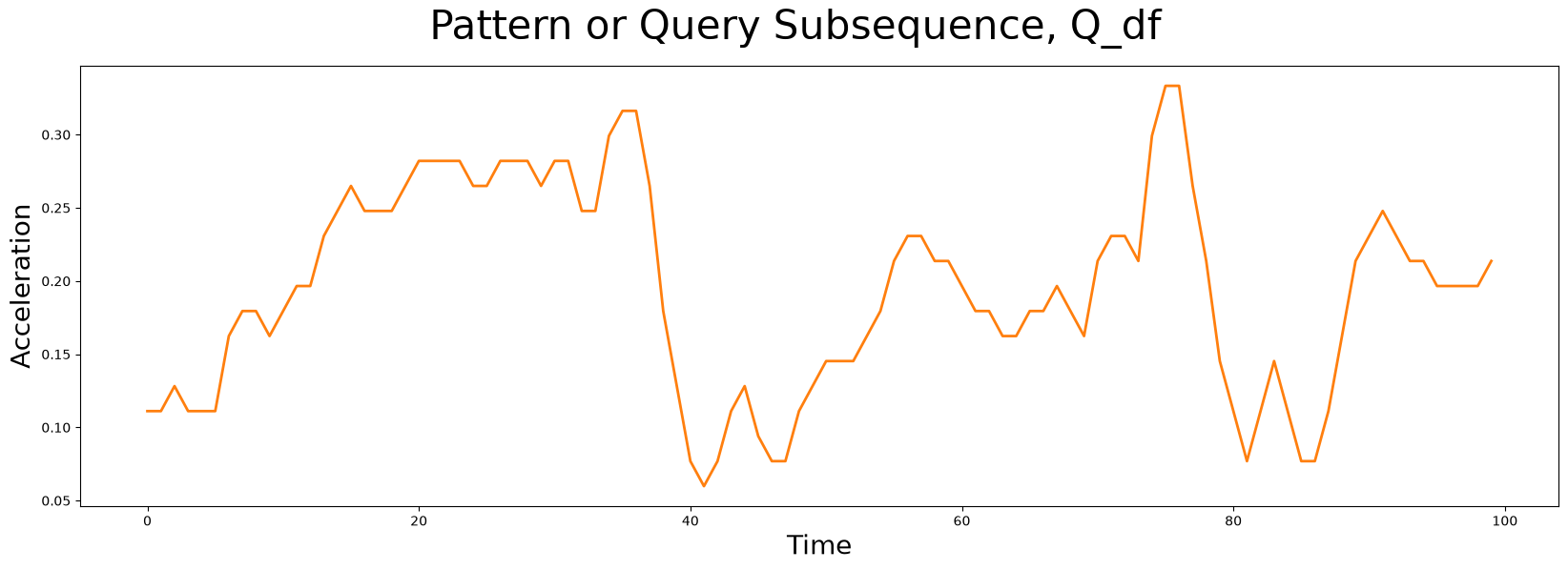
This pattern, Q_df, has a window length of m = 100 and it was taken from a completely independent walking sample. Does it look familiar at all? Does a similar pattern exist in our earlier time series, T_df? Can you tell which surface the robot dog was walking on when this query sample was collected?
To answer some of these questions, you can compare this specific query subsequence or pattern with the full time series by computing something called a “distance profile”. Essentially, you take this single query, Q_df, and compare it to every single subsequence in T_df by computing all possible (z-normalized Euclidean) pairwise distances. So, the distance profile is simply a 1-dimensional vector that tells you exactly how similar/dissimilar Q_df is to every subsequence (of the same length) found in T_df. Now, a naive algorithm for computing the distance profile would take O(n*m) time to process but, luckily, we can do much better than this as there exists a super efficient approach called “Mueen’s Algorithm for Similarity Search” (MASS) that is able to compute the distance profile in much faster O(n*log(n)) time (log base 2). Now, this may not be a big deal if you only have a few short time series to analyze but if you need to repeat this process many times with different query subsequences then things can add up quickly. In fact, as the length of the time series, n, and/or the length of the query subsequence, m, gets much longer, the naive algorithm would take way too much time!
Computing the Distance Profile with MASS#
So, given a query subsequence, Q_df, and a time series, T_df, we can perform a fast similarity search and compute a distance profile using the stumpy.mass function in STUMPY:
distance_profile = stumpy.mass(Q_df["Acceleration"], T_df["Acceleration"])
And, since the distance_profile contains the full list of pairwise distances between Q_df and every subsequence within T_df, we can retrieve the most similar subsequence from T_df by finding the smallest distance value in distance_profile and extracting its positional index:
idx = np.argmin(distance_profile)
print(f"The nearest neighbor to `Q_df` is located at index {idx} in `T_df`")
The nearest neighbor to `Q_df` is located at index 7479 in `T_df`
So, to answer our earlier question of “Does a similar pattern exist in our earlier time series, T_df?”, let’s go ahead and plot the most similar subsequence in T_df, which is located at index 7479 (blue), and overlay this with our query pattern, Q_df, (orange):
# Since MASS computes z-normalized Euclidean distances, we should z-normalize our subsequences before plotting
Q_z_norm = stumpy.core.z_norm(Q_df.values)
nn_z_norm = stumpy.core.z_norm(T_df.values[idx:idx+len(Q_df)])
plt.suptitle('Comparing The Query To Its Nearest Neighbor', fontsize='30')
plt.xlabel('Time', fontsize ='20')
plt.ylabel('Acceleration', fontsize='20')
plt.plot(Q_z_norm, lw=2, color="C1", label="Query Subsequence, Q_df")
plt.plot(nn_z_norm, lw=2, label="Nearest Neighbor Subsequence From T_df")
plt.legend()
plt.show()
/home/docs/checkouts/readthedocs.org/user_builds/stumpy/envs/latest/lib/python3.11/site-packages/stumpy/core.py:380: UserWarning: 'where' used without 'out', expect unitialized memory in output. If this is intentional, use out=None.
std[np.less(std, threshold, where=~np.isnan(std))] = 1.0
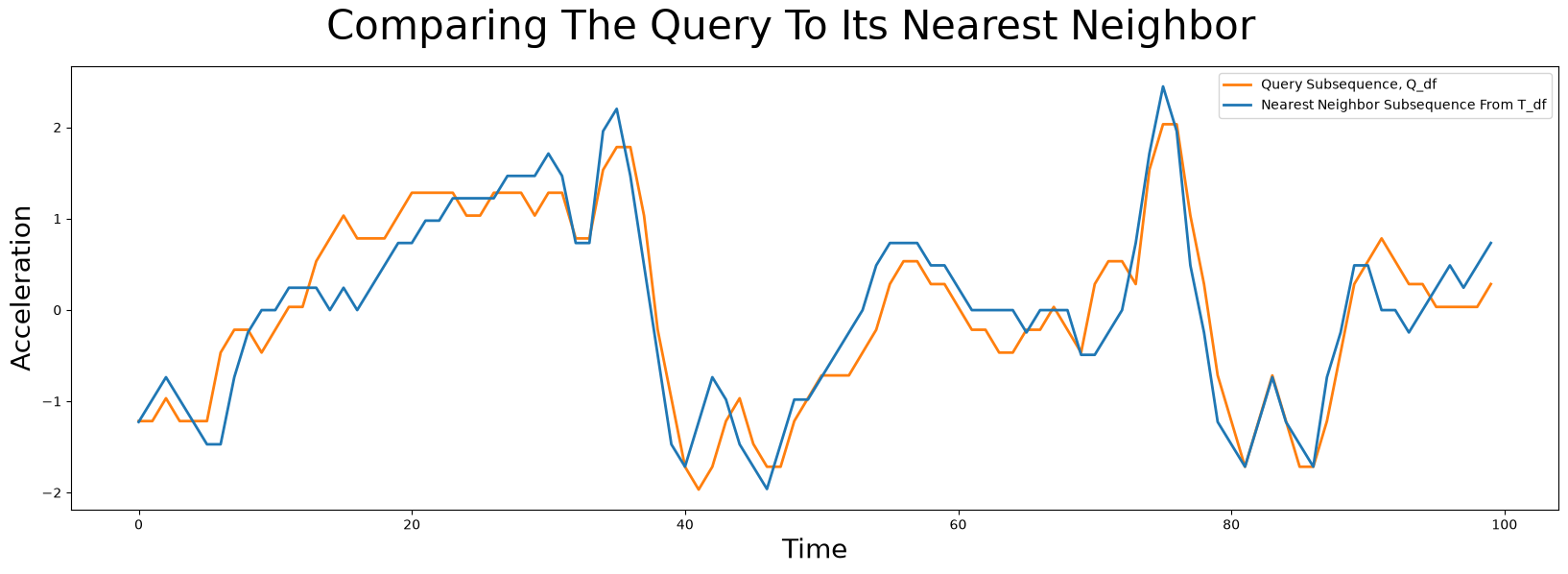
Notice that even though the query subsequence does not perfectly match its nearest neighbor, STUMPY was still able to find it! And then, to answer the second question of “Can you tell which surface the robot dog was walking on when this query sample was collected?”, we can look at precisely where idx is located within T_df:
plt.suptitle('Sony AIBO Robot Dog Dataset, T_df', fontsize='30')
plt.xlabel('Time', fontsize ='20')
plt.ylabel('Acceleration', fontsize='20')
plt.plot(T_df)
plt.text(2000, 4.5, 'Cement', color="black", fontsize=20)
plt.text(10000, 4.5, 'Cement', color="black", fontsize=20)
ax = plt.gca()
rect = Rectangle((5000, -4), 3000, 10, facecolor='lightgrey')
ax.add_patch(rect)
plt.text(6000, 4.5, 'Carpet', color="black", fontsize=20)
plt.plot(range(idx, idx+len(Q_df)), T_df.values[idx:idx+len(Q_df)], lw=2, label="Nearest Neighbor Subsequence")
plt.legend()
plt.show()
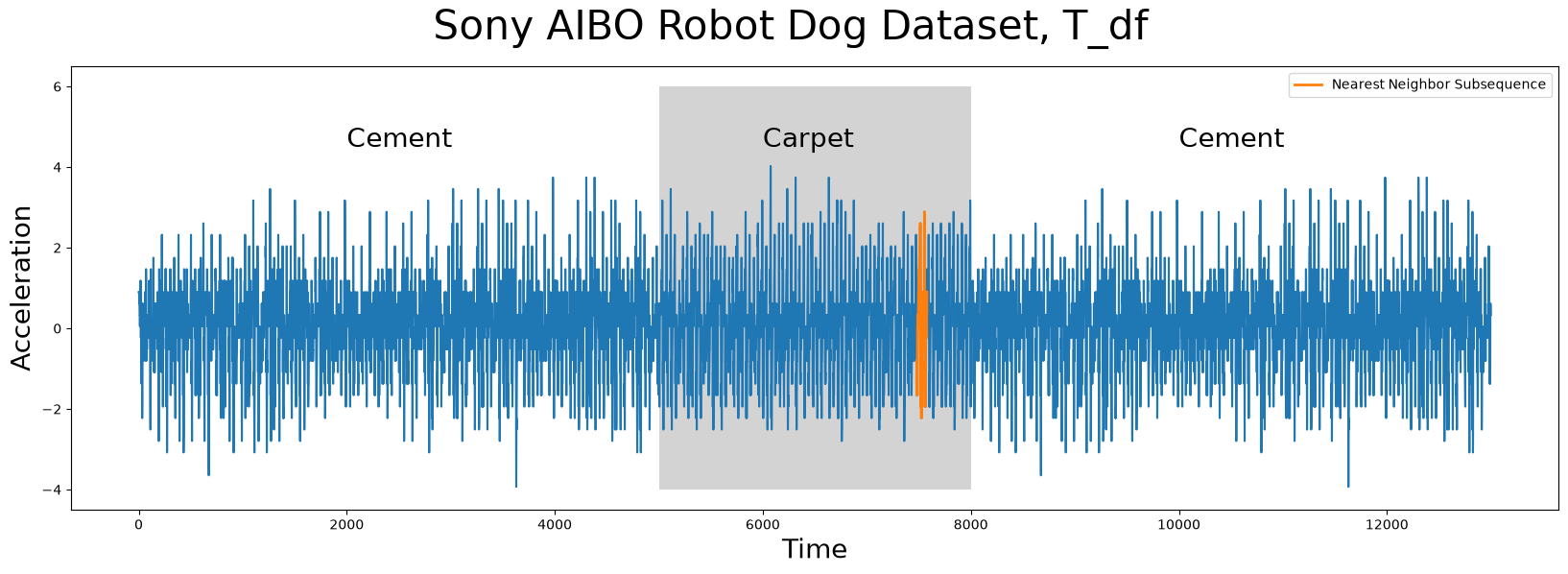
As we can see above, the nearest neighbor (orange) to Q_df is a subsequence that is found when the robot dog was walking on carpet and, as it turns out, the Q_df was collected from an independent sample where the robot dog was walking on carpet too! To take this a step further, instead of only extracting the top nearest neighbor, we can look at where the top k = 16 nearest neighbors are located:
# This simply returns the (sorted) positional indices of the top 16 smallest distances found in the distance_profile
k = 16
idxs = np.argpartition(distance_profile, k)[:k]
idxs = idxs[np.argsort(distance_profile[idxs])]
And then let’s plot all of these subsequences based on their index locations:
plt.suptitle('Sony AIBO Robot Dog Dataset, T_df', fontsize='30')
plt.xlabel('Time', fontsize ='20')
plt.ylabel('Acceleration', fontsize='20')
plt.plot(T_df)
plt.text(2000, 4.5, 'Cement', color="black", fontsize=20)
plt.text(10000, 4.5, 'Cement', color="black", fontsize=20)
ax = plt.gca()
rect = Rectangle((5000, -4), 3000, 10, facecolor='lightgrey')
ax.add_patch(rect)
plt.text(6000, 4.5, 'Carpet', color="black", fontsize=20)
for idx in idxs:
plt.plot(range(idx, idx+len(Q_df)), T_df.values[idx:idx+len(Q_df)], lw=2)
plt.show()
Unsurprisingly, the top k = 16 nearest neighbors to Q_df (or best matches, shown in multiple colors above) can all be found when the robot dog was walking on the carpet (grey)!
Levaraging STUMPY To Do Some Work For You#
Until now, you’ve learned how to search for similar matches to your query using a raw distance profile. While this is feasible, STUMPY provides you with a super powerful function called stumpy.match that does even more work for you. One benefit of using stumpy.match is that, as it discovers each new neighbor, it applies an exclusion zone around it and this ensures that every match that is returned is actually a unique occurrence of your input query. In this section we will explore how to use it to produce the same results as above.
First, we will call stumpy.match only with the two required parameters, Q, your query, and T, the time series you want to search within:
matches = stumpy.match(Q_df["Acceleration"], T_df["Acceleration"])
stumpy.match returns a 2D numpy array, matches, which contains all matches of Q in T sorted by distance. The first column represents the (z-normalized) distance of each match to Q, while the second column represents the start index of the match in T. If we look at the very first row, we see that the best match of Q in T starts at position 7479 and has a z-normalized distance of 3.955. This corresponds exactly to the best match from before!
Now, you might wonder which subsequences of T count as matches of Q. Earlier, we manually sorted the distance profile in ascending order and defined the top 16 matches to be the 16 subsequences with the lowest distance. While we can emulate this behavior with stumpy.match (see the end of this section), the preferred way is to return all subsequences in T that are closer to than some threshold. This threshold is controlled specifying the max_distance parameter.
STUMPY tries to find a reasonable default value but, in general, this is very difficult because it largely depends on your particular dataset and/or domain. For example, if you have ECG data of a patient’s heartbeat and you want to match one specific beat, then you may consider using a smaller threshold since your time series may be highly regular. On the other hand, if you try to match a specific word in a voice recording, then you would probably need to use a larger threshold since the exact shape of your match could be influenced by how the speaker pronounces the given word.
Let’s plot all of the discovered matches to see if we need to adjust our threshold:
# Since MASS computes z-normalized Euclidean distances, we should z-normalize our subsequences before plotting
Q_z_norm = stumpy.core.z_norm(Q_df.values)
plt.suptitle('Comparing The Query To All Matches (Default max_distance)', fontsize='30')
plt.xlabel('Time', fontsize ='20')
plt.ylabel('Acceleration', fontsize='20')
for match_distance, match_idx in matches:
match_z_norm = stumpy.core.z_norm(T_df.values[match_idx:match_idx+len(Q_df)])
plt.plot(match_z_norm, lw=2)
plt.plot(Q_z_norm, lw=4, color="black", label="Query Subsequence, Q_df")
plt.legend()
plt.show()
/home/docs/checkouts/readthedocs.org/user_builds/stumpy/envs/latest/lib/python3.11/site-packages/stumpy/core.py:380: UserWarning: 'where' used without 'out', expect unitialized memory in output. If this is intentional, use out=None.
std[np.less(std, threshold, where=~np.isnan(std))] = 1.0
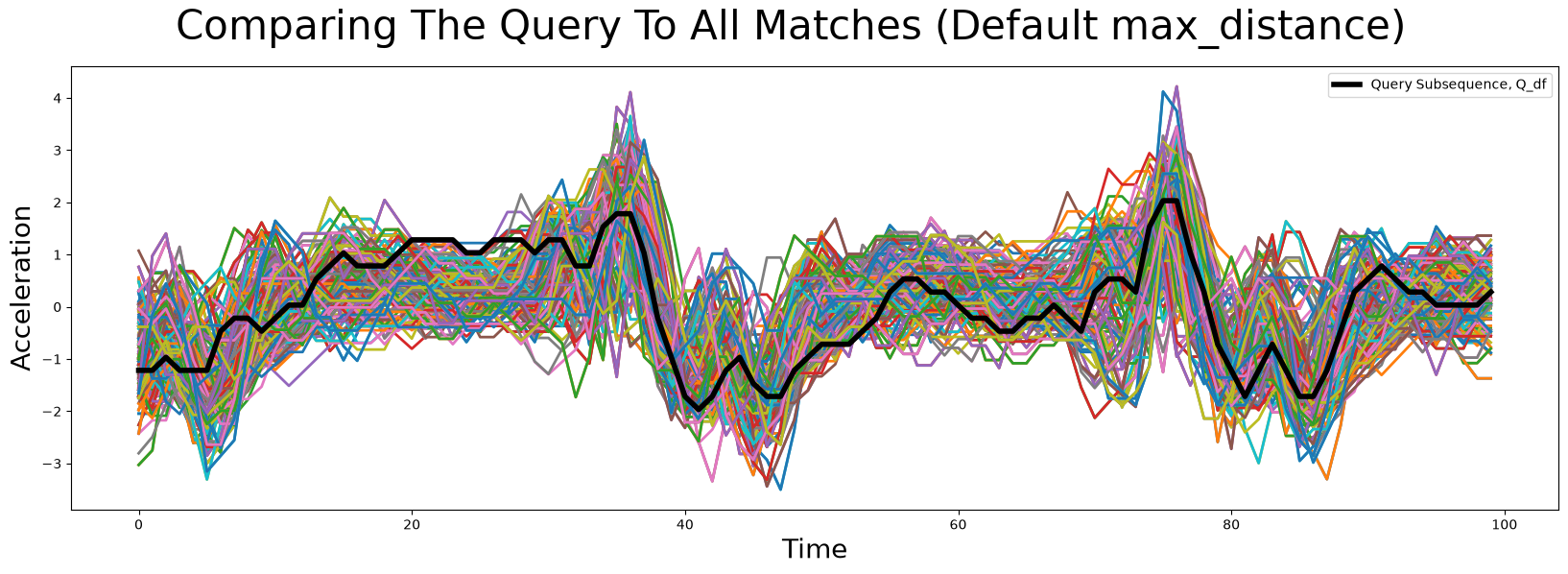
While some of the main features are somewhat conserved across all of the matching subsequences, there seems to be a lot of artifacts as well.
With stumpy.match, you have two options for controlling the matching threshold. You can either specify a constant value (e.g., max_distance = 5.0) or provide a custom function. This function has to take one parameter, which will be the distance profile, D, computed between Q and T. This way, you can encode some dependency on the distance profile into your maximum distance threshold. The default maximum distance is max_distance = max(np.mean(D) - 2 * np.std(D), np.min(D)). This is the typical “two standard deviations below from the mean”.
Of course, one has to experiment a bit with what an acceptable maximum distance so let’s try increasing it to “four standard deviations below the mean” (i.e., a smaller maximum distance).
matches_improved_max_distance = stumpy.match(
Q_df["Acceleration"],
T_df["Acceleration"],
max_distance=lambda D: max(np.mean(D) - 4 * np.std(D), np.min(D))
)
# Since MASS computes z-normalized Euclidean distances, we should z-normalize our subsequences before plotting
Q_z_norm = stumpy.core.z_norm(Q_df.values)
plt.suptitle('Comparing The Query To All Matches (Improved max_distance)', fontsize='30')
plt.xlabel('Time', fontsize ='20')
plt.ylabel('Acceleration', fontsize='20')
for match_distance, match_idx in matches_improved_max_distance:
match_z_norm = stumpy.core.z_norm(T_df.values[match_idx:match_idx+len(Q_df)])
plt.plot(match_z_norm, lw=2)
plt.plot(Q_z_norm, lw=4, color="black", label="Query Subsequence, Q_df")
plt.legend()
plt.show()
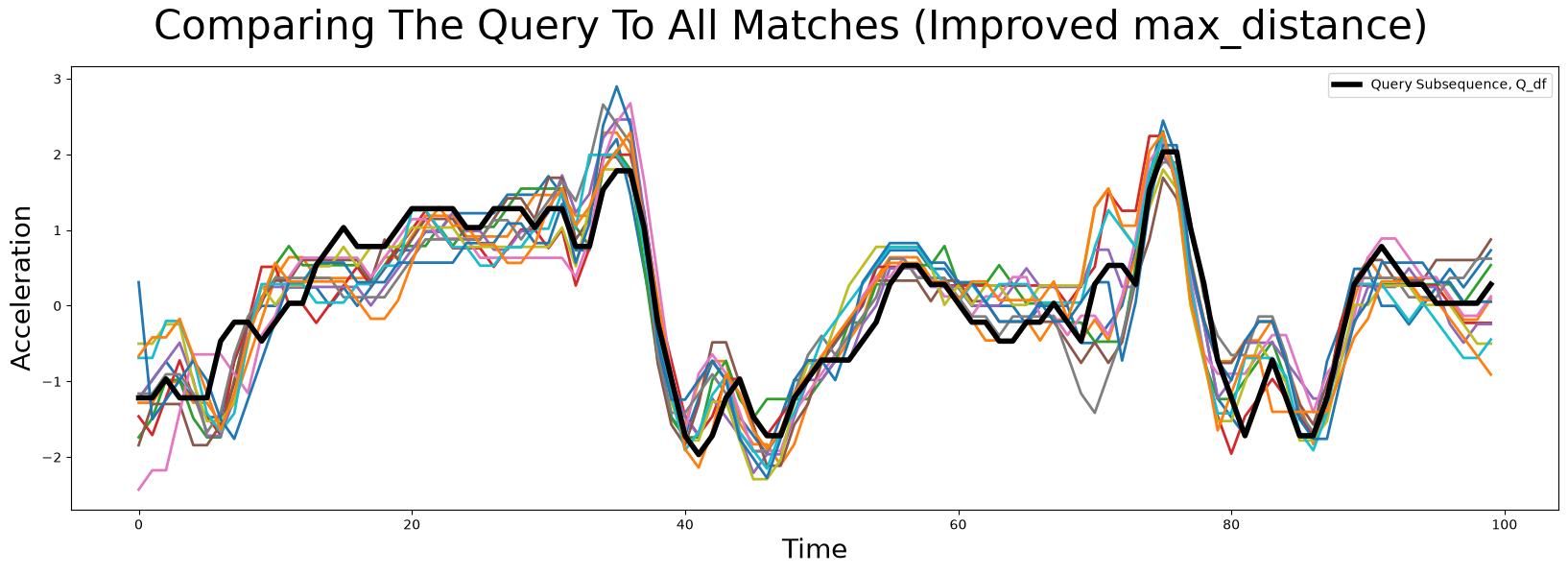
We see that this looks much more promising and we did indeed find very similar looking matches. Sometimes, one still is not interested in all matches in the specified region. The easiest way to adjust this is to set max_matches to the maximum number of matches you want. By default, max_matches = None, which means that all matches will be returned.
Emulating Finding All Top-k Matches#
Sometimes, you may not have decided what a good threshold would be and so you may still want to find the top-k matches. In those cases, you may find the need to deactivate the default exclusion zone altogether so that you can find matches that may be very close to each other (i.e., close index values) in T. This can be done by changing the default exclusion zone of m / 4 (where m is the window size) to zero. In STUMPY, since the exclusion zone is computed as int(np.ceil(m / config.STUMPY_EXCL_ZONE_DENOM)), we can change the exclusion zone by explicitly setting stumpy.config.STUMPY_EXCL_ZONE_DENOM before computing distances:
m = Q_df["Acceleration"].size
# To set the exclusion zone to zero, set the denominator to np.`inf`
stumpy.config.STUMPY_EXCL_ZONE_DENOM = np.inf
matches_top_16 = stumpy.match(
Q_df["Acceleration"],
T_df["Acceleration"],
max_distance=np.inf, # set the threshold to infinity include all subsequences
max_matches=16, # find the top 16 matches
)
stumpy.config.STUMPY_EXCL_ZONE_DENOM = 4 # Reset the denominator to its default value
To show that this does the same as we did in the first part of the tutorial, we will assert that the newly found indices are equal to the indices we found above using the stumpy.mass method.
npt.assert_equal(matches_top_16[:,1], idxs)
No error, this means they are indeed returning the same matches!
Summary#
And that’s it! You have now taken a known pattern of interest (or query), ran it through stumpy.mass using STUMPY, and you were able to quickly search for this pattern in another time series. Moreover, you learned how to use the stumpy.match function, to let stumpy handle a lot of the work for you. With this newfound knowledge, you can now go and search for patterns in your own time series projects. Happy coding!
Additional Note - Distance Profiles with Non-normalized Euclidean Distances#
There are times when you may want to use non-normalized Euclidean distance as your measure of similarity/dissimilarity, and so you can do this by simply setting normalize=False when you are calling stumpy.mass. This same normalize=False parameter is also available for the following set of STUMPY functions: stumpy.stump, stumpy.stumped, stumpy.gpu_stump, and stumpy.stumpi. Additionally, the normalize=False is also available in stumpy.match.
Bonus Section - What Makes MASS So Fast?#
The reason why MASS is so much faster than a naive approach is because MASS uses Fast Fourier Transforms (FFT) to convert the data into the frequency domain and performs what is called a “convolution”, which reduces the m operations down to log(n) operations. You can read more about this in the original Matrix Profile I paper.
Here’s a naive implementation of computing a distance profile:
import time
def compute_naive_distance_profile(Q, T):
Q = Q.copy()
T = T.copy()
n = len(T)
m = len(Q)
naive_distance_profile = np.empty(n - m + 1)
start = time.time()
Q = stumpy.core.z_norm(Q)
for i in range(n - m + 1):
naive_distance_profile[i] = np.linalg.norm(Q - stumpy.core.z_norm(T[i:i+m]))
naive_elapsed_time = time.time()-start
print(f"For n = {n} and m = {m}, the naive algorithm takes {np.round(naive_elapsed_time, 2)}s to compute the distance profile")
return naive_distance_profile
For a random time series, T_random, with 1 million data points and a random query subsequence, Q_random:
Q_random = np.random.rand(100)
T_random = np.random.rand(1_000_000)
naive_distance_profile = compute_naive_distance_profile(Q_random, T_random)
For n = 1000000 and m = 100, the naive algorithm takes 42.9s to compute the distance profile
The naive algorithm takes some time to compute! However, MASS can handle this (and even larger data sets) in a blink of an eye:
start = time.time()
mass_distance_profile = stumpy.mass(Q_random, T_random)
mass_elapsed_time = time.time()-start
print(f"For n = {len(T_random)} and m = {len(Q_random)}, the MASS algorithm takes {np.round(mass_elapsed_time, 2)}s to compute the distance profile")
For n = 1000000 and m = 100, the MASS algorithm takes 0.26s to compute the distance profile
And to be absolutely certain, let’s make sure and check that the output is the same from both methods:
npt.assert_almost_equal(naive_distance_profile, mass_distance_profile)
Success, no errors! This means that both outputs are identical. Go ahead and give it a try!
Resources#
The Fastest Similarity Search Algorithm for Time Series Subsequences Under Euclidean Distance