Consensus Motif Search#
![]()
This tutorial utilizes the main takeaways from the Matrix Profile XV paper.
Matrix profiles can be used to find conserved patterns within a single time series (self-join) and across two time series (AB-join). In both cases these conserved patterns are often called “motifs”. And, when considering a set of three or more time series, one common trick for identifying a conserved motif across the entire set is to:
Append a
np.nanto the end of each time series. This is used to identify the boundary between neighboring time series and ensures that any identified motif will not straddle multiple time series.Concatenate all of the time series into a single long time series
Compute the matrix profile (self-join) on the aforementioned concatenated time series
However, this is not guaranteed to find patterns that are conserved across all of the time series within the set. This idea of a finding a conserved motif that is common to all of the time series in a set is referred to as a “consensus motif”. In this tutorial we will introduce the “Ostinato” algorithm, which is an efficient way to find the consensus motif amongst a set of time series.
Getting started#
Let’s import the packages that we’ll need to load, analyze, and plot the data.
%matplotlib inline
import stumpy
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from matplotlib.patches import Rectangle
from scipy.cluster.hierarchy import linkage, dendrogram
plt.style.use('https://raw.githubusercontent.com/stumpy-dev/stumpy/main/docs/stumpy.mplstyle')
Loading the Eye-tracking (EOG) Dataset#
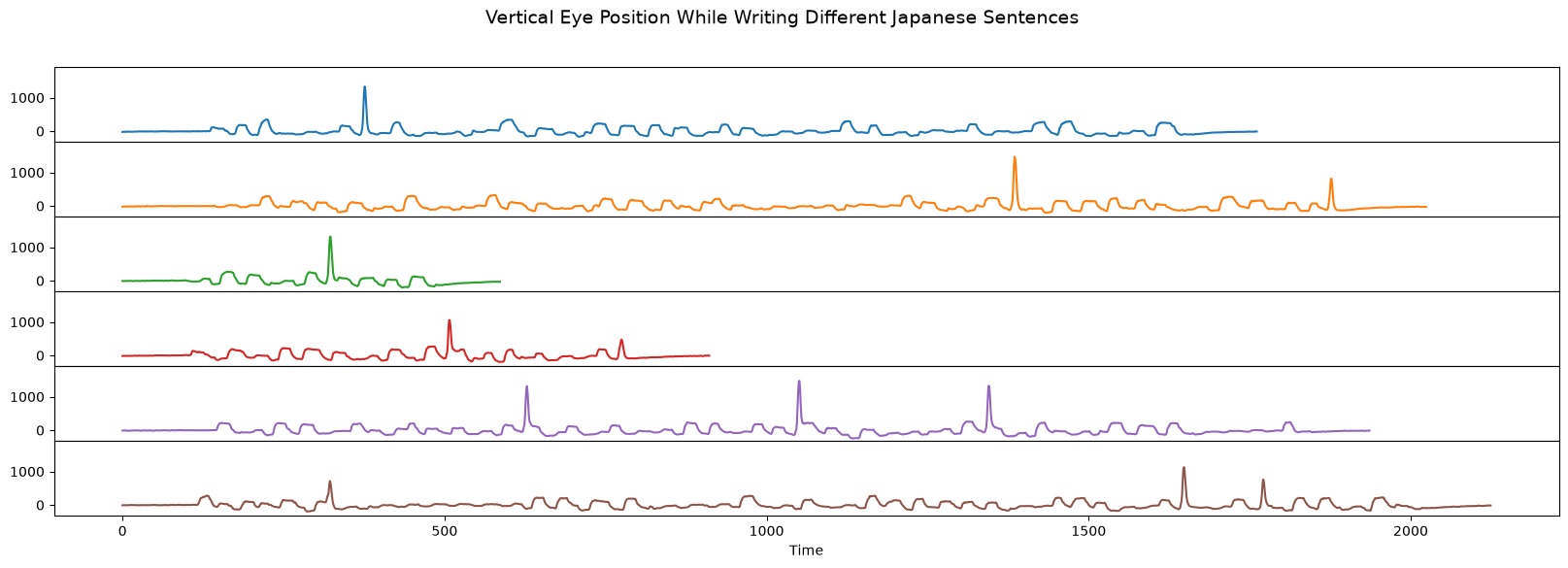
In the following dataset, a volunteer was asked to “spell” out different Japanese sentences by performing eye movements that represented writing strokes of individual Japanese characters. Their eye movements were recorded by an electrooculograph (EOG) and they were given one second to “visually trace” each Japanese character. For our purposes we’re only using the vertical eye positions and, conceptually, this basic example reproduced Figure 1 and Figure 2 of the Matrix Profile XV paper.
Ts = []
for i in [6, 7, 9, 10, 16, 24]:
Ts.append(pd.read_csv(f'https://zenodo.org/record/4288978/files/EOG_001_01_{i:03d}.csv?download=1').iloc[:, 0].values)
Visualizing the EOG Dataset#
Below, we plotted six time series that each represent the vertical eye position while a person “wrote” Japanese sentences using their eyes. As you can see, some of the Japanese sentences are longer and contain more words while others are shorter. However, there is one common Japanese word (i.e., a “common motif”) that is contained in all six examples. Can you spot the one second long pattern that is common across these six time series?
def plot_vertical_eog():
fig, ax = plt.subplots(len(Ts), sharex=True, sharey=True)
colors = plt.rcParams["axes.prop_cycle"]()
for i, T in enumerate(Ts):
ax[i].plot(T, color=next(colors)["color"])
ax[i].set_ylim((-330, 1900))
plt.subplots_adjust(hspace=0)
plt.xlabel('Time')
return ax
plot_vertical_eog()
plt.suptitle('Vertical Eye Position While Writing Different Japanese Sentences', fontsize=14)
plt.show()
Consensus Motif Search#
To find out, we can use the stumpy.ostinato function to help us discover the “consensus motif” by passing in the list of time series, Ts, along with the subsequence window size, m:
m = 50 # Chosen since the eog signal was downsampled to 50 Hz
radius, Ts_idx, subseq_idx = stumpy.ostinato(Ts, m)
print(f'Found Best Radius {np.round(radius, 2)} in time series {Ts_idx} starting at subsequence index location {subseq_idx}.')
Found Best Radius 0.87 in time series 4 starting at subsequence index location 1271.
Now, Let’s plot the individual subsequences from each time series that correspond to the matching consensus motif:
consensus_motif = Ts[Ts_idx][subseq_idx : subseq_idx + m]
nn_idx = []
for i, T in enumerate(Ts):
nn_idx.append(np.argmin(stumpy.core.mass(consensus_motif, T)))
lw = 1
label = None
if i == Ts_idx:
lw = 4
label = 'Consensus Motif'
plt.plot(stumpy.core.z_norm(T[nn_idx[i] : nn_idx[i]+m]), lw=lw, label=label)
plt.title('The Consensus Motif (Z-normalized)')
plt.xlabel('Time (s)')
plt.legend()
plt.show()
/home/docs/checkouts/readthedocs.org/user_builds/stumpy/envs/latest/lib/python3.11/site-packages/stumpy/core.py:380: UserWarning: 'where' used without 'out', expect unitialized memory in output. If this is intentional, use out=None.
std[np.less(std, threshold, where=~np.isnan(std))] = 1.0
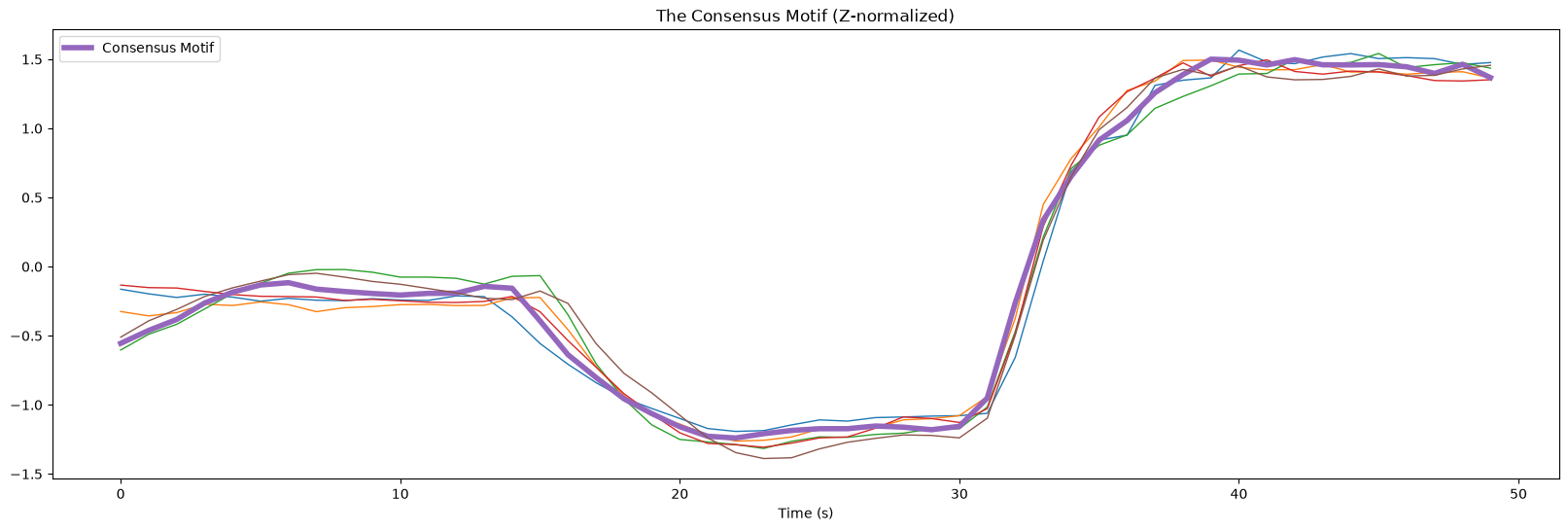
There is a striking similarity between the subsequences. The most central “consensus motif” is plotted with a thicker purple line.
When we highlight the above subsequences in their original context (light blue boxes below), we can see that they occur at different times:
ax = plot_vertical_eog()
ymin, ymax = ax[i].get_ylim()
for i in range(len(Ts)):
r = Rectangle((nn_idx[i], ymin), m, ymax-ymin, alpha=0.3)
ax[i].add_patch(r)
plt.suptitle('Vertical Eye Position While Writing Different Japanese Sentences', fontsize=14)
plt.show()
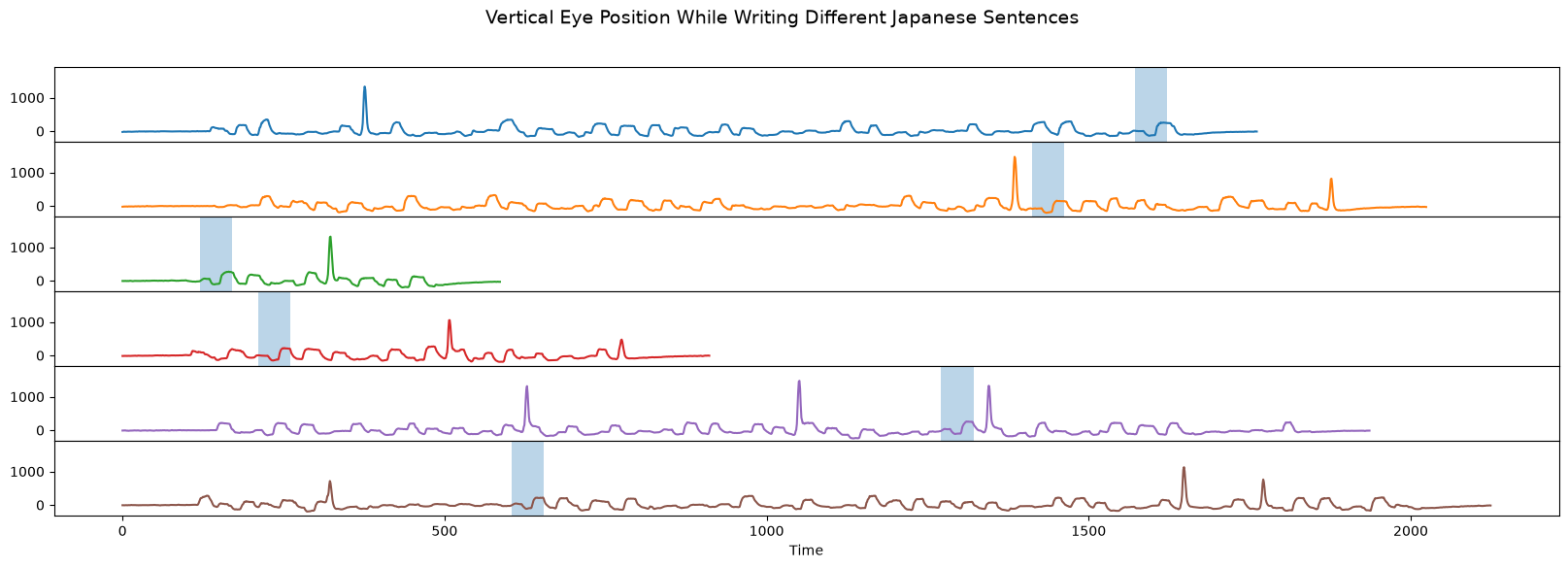
The discovered conserved motif (light blue boxes) correspond to writing the Japanese character ア, which occurs at different times in the different example sentences.
Phylogeny Using Mitochondrial DNA (mtDNA)#
In this next example, we’ll reproduce Figure 9 from the Matrix Profile XV paper.
Mitochondrial DNA (mtDNA) has been successfully used to determine evolutionary relationships between organisms (phylogeny). Since DNAs are essentially ordered sequences of letters, we can loosely treat them as time series and use all of the available time series tools.
Loading the mtDNA Dataset#
animals = ['python', 'hippo', 'red_flying_fox', 'alpaca']
dna_seqs = {}
truncate = 15000
for animal in animals:
dna_seqs[animal] = pd.read_csv(f"https://zenodo.org/record/4289120/files/{animal}.csv?download=1").iloc[:truncate, 0].values
colors = {'python': 'tab:blue', 'hippo': 'tab:green', 'red_flying_fox': 'tab:purple', 'alpaca': 'tab:red'}
Clustering Using Large mtDNA Sequences#
Naively, using scipy.cluster.hierarchy we can cluster the mtDNAs based on the majority of the sequences. A correct clustering would place the two “artiodactyla”, hippo and alpaca, closest and, together with the red flying fox, we would expect them to form a cluster of “mammals”. Finally, the python, a “reptile”, should be furthest away from all of the “mammals”.
fig, ax = plt.subplots(ncols=2)
# Left
for animal, dna_seq in dna_seqs.items():
ax[0].plot(dna_seq, label=animal, color=colors[animal])
ax[0].legend()
ax[0].set_xlabel('Number of mtDNA Base Pairs')
ax[0].set_title('mtDNA Sequences')
# Right
pairwise_dists = []
for i, animal_1 in enumerate(animals):
for animal_2 in animals[i+1:]:
pairwise_dists.append(stumpy.core.mass(dna_seqs[animal_1], dna_seqs[animal_2]).item())
Z = linkage(pairwise_dists, optimal_ordering=True)
dendrogram(Z, labels=animals, ax=ax[1])
ax[1].set_ylabel('Z-normalized Euclidean Distance')
ax[1].set_title('Clustering')
plt.show()
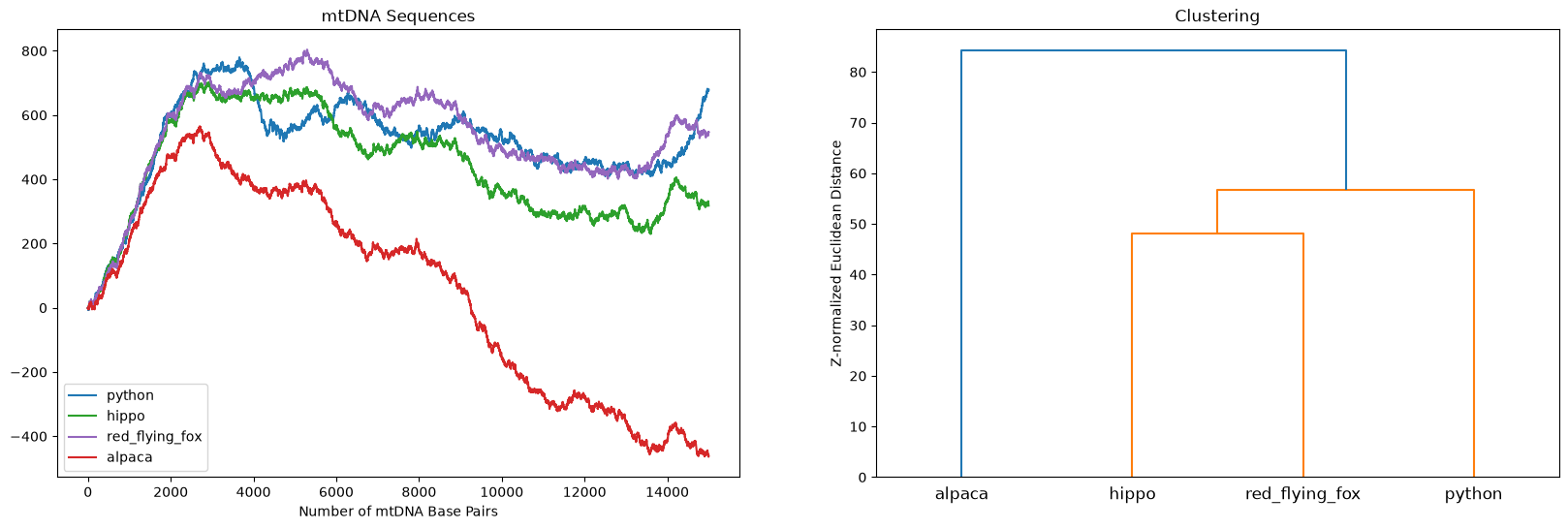
Uh oh, the clustering is clearly wrong! Amongst other problems, the alpaca (a mammal) should not be most closely related to the python (a reptile).
Consensus Motif Search#
In order to obtain the correct relationships, we need to identify and then compare the parts of the mtDNA that is the most conserved across the mtDNA sequences. In other words, we need to cluster based on their consensus motif. Let’s limit the subsequence window size to 1,000 base pairs and identify the consensus motif again using the stumpy.ostinato function:
m = 1000
radius, Ts_idx, subseq_idx = stumpy.ostinato(list(dna_seqs.values()), m)
print(f'Found best radius {np.round(radius, 2)} in time series {Ts_idx} starting at subsequence index location {subseq_idx}.')
Found best radius 2.73 in time series 1 starting at subsequence index location 602.
Clustering Using the Consensus mtDNA Motif#
Now, let’s perform the clustering again but, this time, using the consensus motif:
consensus_motif = list(dna_seqs.values())[Ts_idx][subseq_idx : subseq_idx + m]
# Extract Animal DNA Subsequence Closest to the Consensus Motif
dna_subseqs = {}
for animal in animals:
idx = np.argmin(stumpy.core.mass(consensus_motif, dna_seqs[animal]))
dna_subseqs[animal] = stumpy.core.z_norm(dna_seqs[animal][idx : idx + m])
fig, ax = plt.subplots(ncols=2)
# Left
for animal, dna_subseq in dna_subseqs.items():
ax[0].plot(dna_subseq, label=animal, color=colors[animal])
ax[0].legend()
ax[0].set_title('Consensus mtDNA Subsequences (Z-normalized)')
ax[0].set_xlabel('Number of mtDNA Base Pairs')
# Right
pairwise_dists = []
for i, animal_1 in enumerate(animals):
for animal_2 in animals[i+1:]:
pairwise_dists.append(stumpy.core.mass(dna_subseqs[animal_1], dna_subseqs[animal_2]).item())
Z = linkage(pairwise_dists, optimal_ordering=True)
dendrogram(Z, labels=animals, ax=ax[1])
ax[1].set_title('Clustering Using the Consensus mtDNA Subsequences')
ax[1].set_ylabel('Z-normalized Euclidean Distance')
plt.show()
/home/docs/checkouts/readthedocs.org/user_builds/stumpy/envs/latest/lib/python3.11/site-packages/stumpy/core.py:380: UserWarning: 'where' used without 'out', expect unitialized memory in output. If this is intentional, use out=None.
std[np.less(std, threshold, where=~np.isnan(std))] = 1.0
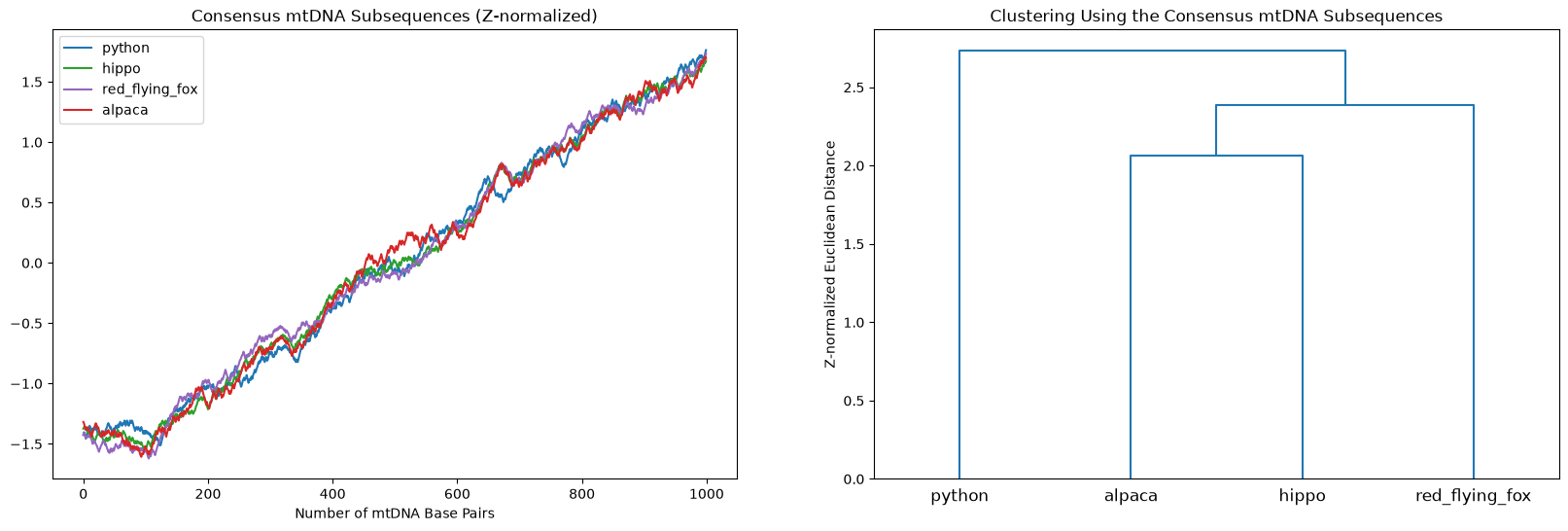
Now this looks much better! Hierarchically, the python is “far away” from the other mammals and, amongst the mammalia, the red flying fox (a bat) is less related to both the alpaca and the hippo which are the closest evolutionary relatives in this set of animals.
Summary#
And that’s it! You have now learned how to search for a consensus motif amongst a set of times series using the awesome stumpy.ostinato function. You can now import this package and use it in your own projects. Happy coding!